
Article Figures & Data
Figures
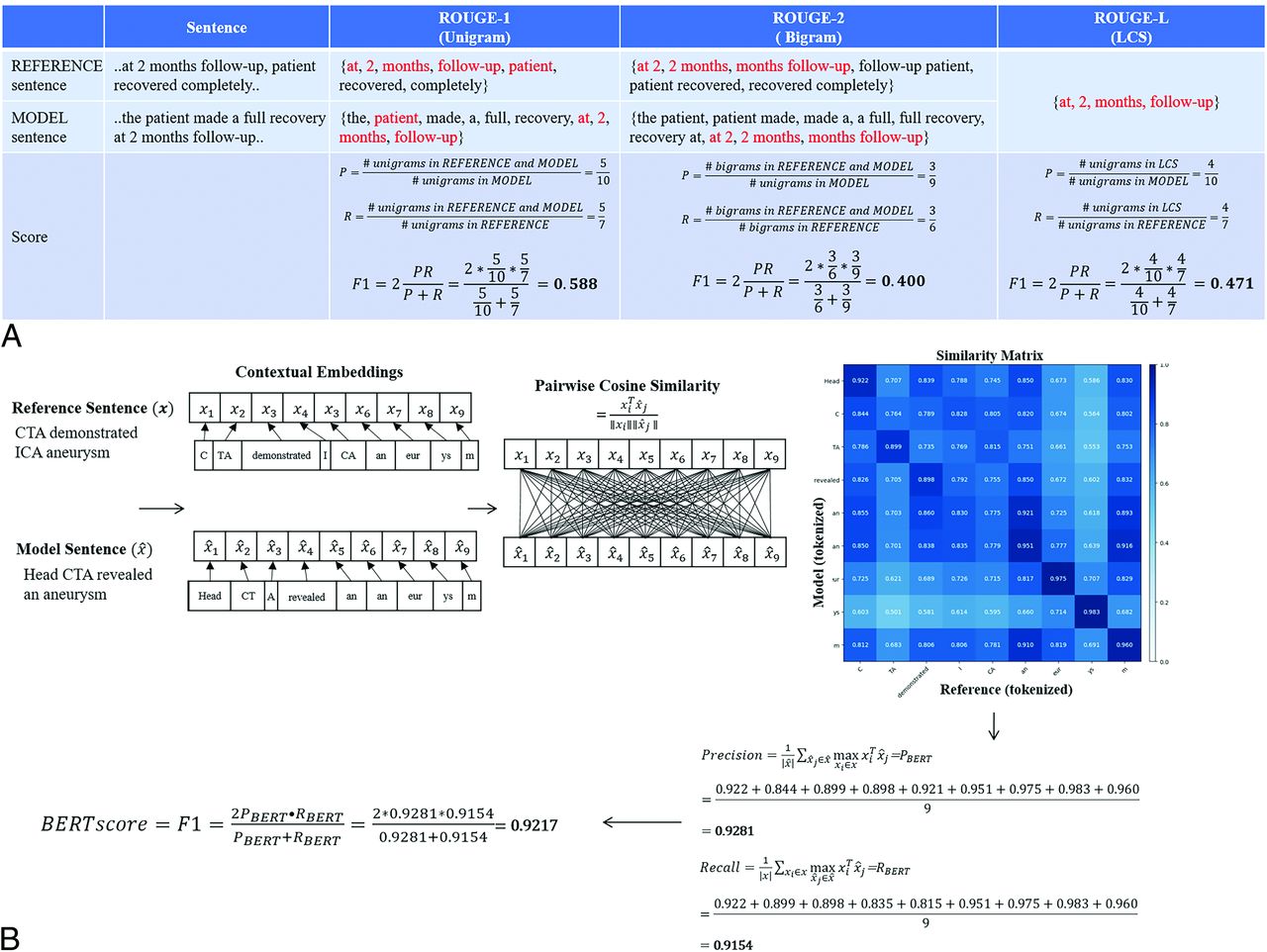
- FIGURE.
Visualization of quantitative evaluation with examples. The example gives expert generated reference sentence and model-generated sentences. A, Different ROUGE scores are calculated based on defining unigrams, bigrams, and longest common subsequences. Matching between the reference and candidate sentences are highlighted in red. ROUGE-1, ROUGE-2, and ROUGE-L are computed as F1 scores using P (precision) and R (recall) values. B, BERTscore was calculated by 1) first converting text into tokens, 2) calculating pair-wise cosine similarity between every reference and model token, and 3) identifying the tokens in the other sentence with the highest similarity value, and using the highest similarity values to calculate F1.





{kind=link}